Dans cette section, on cherche à établir les résultats permettant de fournir une mesure de la précision des estimés effectués par une méthode d’estimation quelconque (généralement linéaire).
Soit une variable aléatoire que l’on veut estimer à partir d’une combinaison linéaire des valeurs observées en différents points :
où :
est la valeur observée au point (v.a.),
est l’estimateur de ,
est le poids associés à la donnée .
On définit l’erreur d’estimation comme la différence entre la valeur estimée et la valeur réelle:
La variance de cette erreur, appelée variance d’estimation, est obtenue par ce développement :
Rappel : Propriété de la variance sur une combinaison linéaire
En substituant l’expression de dans cette formule, on obtient :
Interprétation¶
La variance d’estimation est donc composée de trois termes. Leur interprétation est foncièrement logique et nous allons en explorer les bases ici.
a) : Le phénomène que l’on cherche à estimer est-il intrinsèquement variable ou non ? Plus le phénomène que l’on étudie est variable, plus les erreurs de nos estimations seront également variables. Imaginons estimer une teneur à partir d’un champ constant. C’est assez simple : l’estimation sera la valeur constante et il n’y a aucune variabilité, donc l’estimation est facile. Si le champ est un bruit pur de grande variabilité, l’estimation devient complexe car la variance est élevée.
b) : Quel est le degré de redondance entre les observations ? Ce terme cherche à prendre en compte la redondance des données. L’estimation sera meilleure si les données sont éloignées les unes des autres (ce qui induit une covariance faible), et donc une variance d’estimation réduite. En revanche, si les données sont trop proches les unes des autres, sera élevée et notre estimation sera moins fiable. Ce terme calcule donc la redondance entre les données, et l’objectif est de minimiser cet effet. Il est inutile d’avoir 100 données toutes situées dans la même zone ; au contraire, il est préférable de bien les répartir sur la grille, en tenant compte de l’anisotropie du phénomène étudié, bien sûr.
c) : Les observations sont-elles bien placées par rapport à ce que l’on veut estimer ? Ce terme tient compte de la position des données par rapport à ce que l’on veut estimer. Il est évident que si les données sont très proches du point à estimer, l’estimation sera meilleure. Si est élevé et que ce terme est précédé d’un signe négatif, la variance d’estimation sera réduite. Inversement, si les données sont très éloignées, tendra vers 0 et n’aura pas d’effet sur la réduction de la variance d’estimation. Au final, il est très difficile d’estimer un point précisément lorsque les données sont à des années-lumière de ce que l’on cherche à estimer.
Remarques importantes¶
Dans les formules ci-dessus, on reconnaît trois composantes :
Un terme lié au bloc à estimer : ou
Un terme lié aux points utilisés pour estimer : ou
Un terme croisé : ou
La variance d’estimation est une mesure de précision moyenne sur le gisement pour une configuration donnée. Elle est indépendante de la valeur estimée et ne prend pas en compte les effets proportionnels (ex. : gisement lognormal).
Pour améliorer la précision, on peut chercher à minimiser en choisissant les poids de façon optimale — c’est le principe du krigeage.
Variance d’extension¶
C’est la variance d’estimation obtenue lorsqu’on étend la valeur d’un point à une surface ou un volume; la valeur d’un segment à une surface ou un volume; la valeur d’une surface à un volume, etc. Bref, il s’agit de variances d’estimation correspondant à des situations particulières qui, par leur simplicité, se prêtent bien à la construction d’abaques.
Les configurations seront introduites dans la section calcul.
Formulation avec le variogramme¶
En utilisant la relation qui relie la covariance et le variogramme :
Il est possible d’écrire la variance d’estimation en termes du variogramme comme suit :
Combinaison d’erreurs élémentaires¶
Quand on dispose de nombreuses observations et que l’on souhaite estimer une moyenne sur un grand volume, le calcul direct de la variance d’estimation peut devenir lourd. Une approche simplifiée consiste à utiliser le principe de combinaison des erreurs élémentaires, qui décompose l’estimation globale en une série d’estimations locales approximativement indépendantes.
i. Grille régulière¶
Pour une grille régulière, l’estimé global est simplement :
Chaque point est supposé représenter un bloc de taille égale. Si la variance d’erreur pour chaque bloc est , la variance d’estimation globale est :
Les erreurs sont approximativement indépendantes, car chaque bloc est estimé avec un seul point.
ii. Échantillonnage aléatoire uniforme (stratifié)¶
Chaque point représente un bloc positionné aléatoirement dans le domaine. Pour un bloc , la variance d’estimation est :
Donc la variance d’estimation globale est encore :
iii. Échantillonnage quelconque¶
Supposons que nous somme en mesure de calculer la variance d’estimation sur un sous domaine . Ainsi, pour l’ensemble du domaine , l’estimé est obtenu en combinant, selon des poids proportionnels aux volumes des sous-domaines, les différents estimés obtenus. On aura donc :
et la variance d’estimation sera, puisque chaque erreur est considérée indépendante :
où les variances d’estimation élémentaires sont celles correspondant aux différents sous-domaines que l’on a pu reconnaître.
Remarques¶
L’estimateur particulier utilisé pour obtenir l’estimé pour la moyenne du champ n’intervient pas dans le calcul de la variance d’estimation globale par la méthode des erreurs élémentaires. L’estimation aurait pu être obtenu par krigeage, par inverse de la distance, par méthode polygonale, etc.. La raison de cette apparente anomalie est que les estimés globaux obtenus par ces méthodes sont très similaires. Ils consistent plus ou moins en une moyenne, pondérée par la zone d’influence de chaque observation, des valeurs observées. Puisque les estimations sont similaires, il n’est pas surprenant qu’elles aient toutes à peu près la même précision. Ce raisonnement n’est pas vrai si l’on cherche à prédire les variances d’estimation pour une estimation locale, i.e. pour une petite portion du champ. Alors, la technique d’estimation utilisée a une forte influence sur la précision obtenue
Si l’on dispose d’un programme permettant d’effectuer le krigeage et de calculer les variances de krigeage (variance d’estimation), alors on peut les combiner suivant le principe précédent, i.e. il suffit de segmenter le domaine en blocs et d’estimer chaque bloc en n’utilisant que les données qui s’y trouvent, puis de combiner les variances de krigeage en fonction de la taille des blocs comme l’indique la formule précédente. Il est important de ne pas avoir des données communes pour l’estimation de deux blocs car alors les erreurs d’estimation ne pourraient plus être considérées comme indépendantes.
Exemple¶
Une zone a été estimée directement par krigeage (variance d’estimation 0.36) puis par combinaison de 4 parcelles selon 2 scénarios différents (Fig. 1). Pour l’estimation de chaque parcelle, on n’utilise que les points s’y retrouvant. On calcule les variances d’estimation pour chaque parcelle et on combine le tout suivant le carré des surfaces de chaque parcelle. Les résultats obtenus par subdivision, dans les deux cas, sont quasi-identiques au résultat direct.
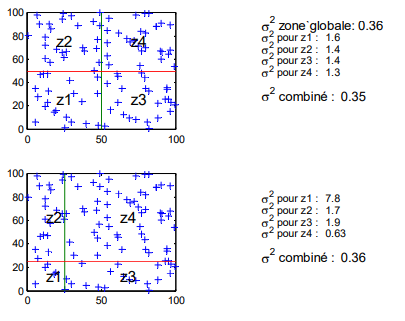
Figure 1:Illustration des paramètres du variogramme - effet de pépite, palier et portée.